
Fun with Trove Newspapers
The NLA’s Trove Newspapers database is a magnificent resource for digital history, but it’s currently not very easy to do detailed analysis of content. I’ve been working on a few tools which make this easier and I’d be interested in giving a bit of a how-to session to explain them and the technologies they use and kick off a ‘what next’ discusión.
At the base of my tools is a screen-scraper which, in the absence of an official API, retrieves article information in machine-readable form. I’ve used this to create a harvester, which you can use to dump the results of your search to a CSV file for further analysis. It can also retrieve text and pdf versions of the articles. You can read more about the havester on my blog.
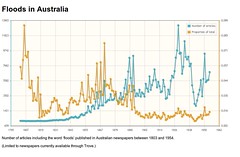 To provide a more quick and dirty picture of search results over time, I’ve created another little harvest tool that gets the number of results for each year and calculates what proportion this is of total articles (in Trove) for that year. I’ve used this to create a few interactive graphs as a demonstration.
To provide a more quick and dirty picture of search results over time, I’ve created another little harvest tool that gets the number of results for each year and calculates what proportion this is of total articles (in Trove) for that year. I’ve used this to create a few interactive graphs as a demonstration.
I’ve also used the scraper to create my own ‘unofficial’ Newspapers API on Google App Engine. I put this up to encourage people to have a play and think about the possibilities.
Depending on people’s interests I’m happy to walk through the development of these tools as well as describing how to use them.
But I’m also very interested in talking about further possibilities for analysing and visualising the results. I’ve been playing around with VoyeurTools, but I wonder what other ideas people have. What about comparisons with other data sources like Google’s ngrams? What other tools do we need? What other databases should we mine?
And lastly it would be good to talk about how we engage directly with the NLA to build a community of digital researchers and help encourage the development of tools like APIs.